

システム構成
Solutions

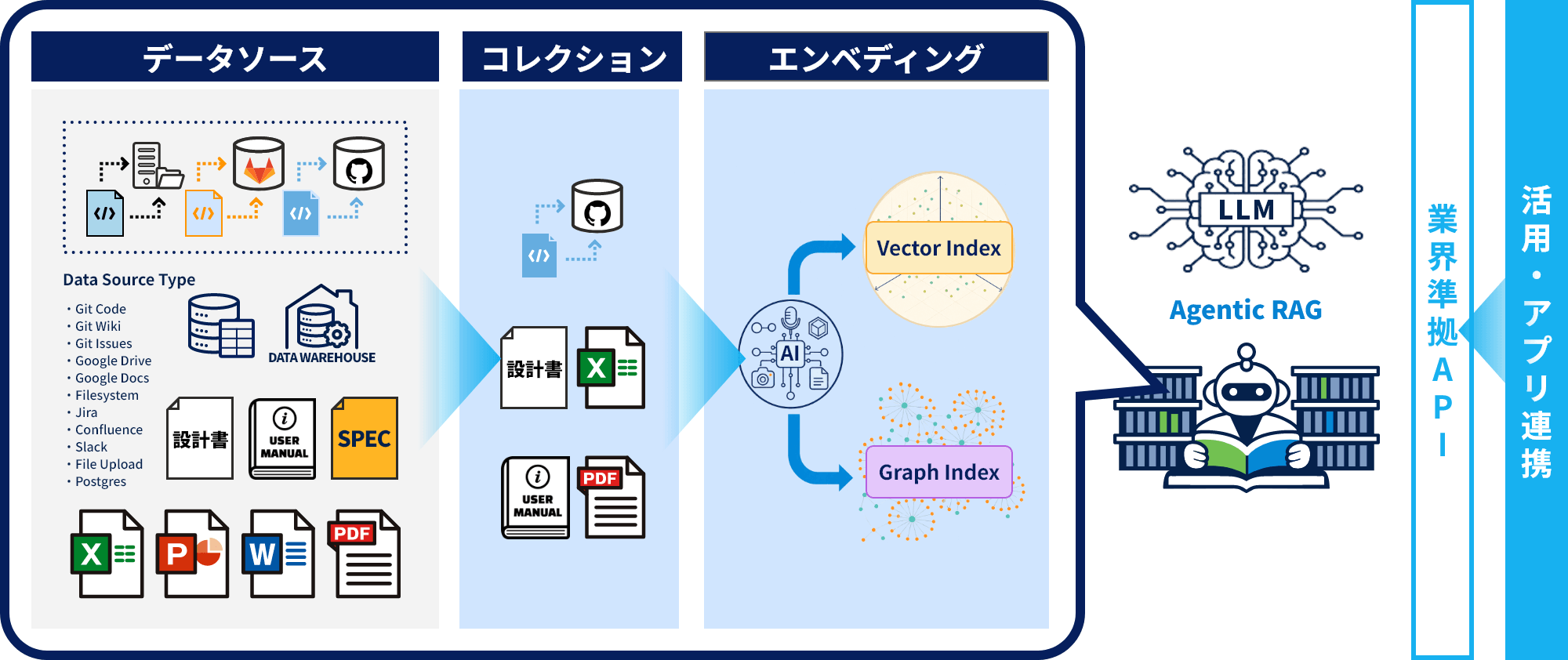
Krugle Biblioは、データソース(コードおよび周辺ドキュメント)に独自の前処理を施し、LLMが読解できるようにします。
これらを目的毎にコレクションし、コレクション内(コードおよび周辺情報)の横断的なベクターインデックスおよびナレッジインデックスを作成します。
Agentic RAGがプロンプトを分析し、更にこのエンベディングされたインデックスを検索して回答します。
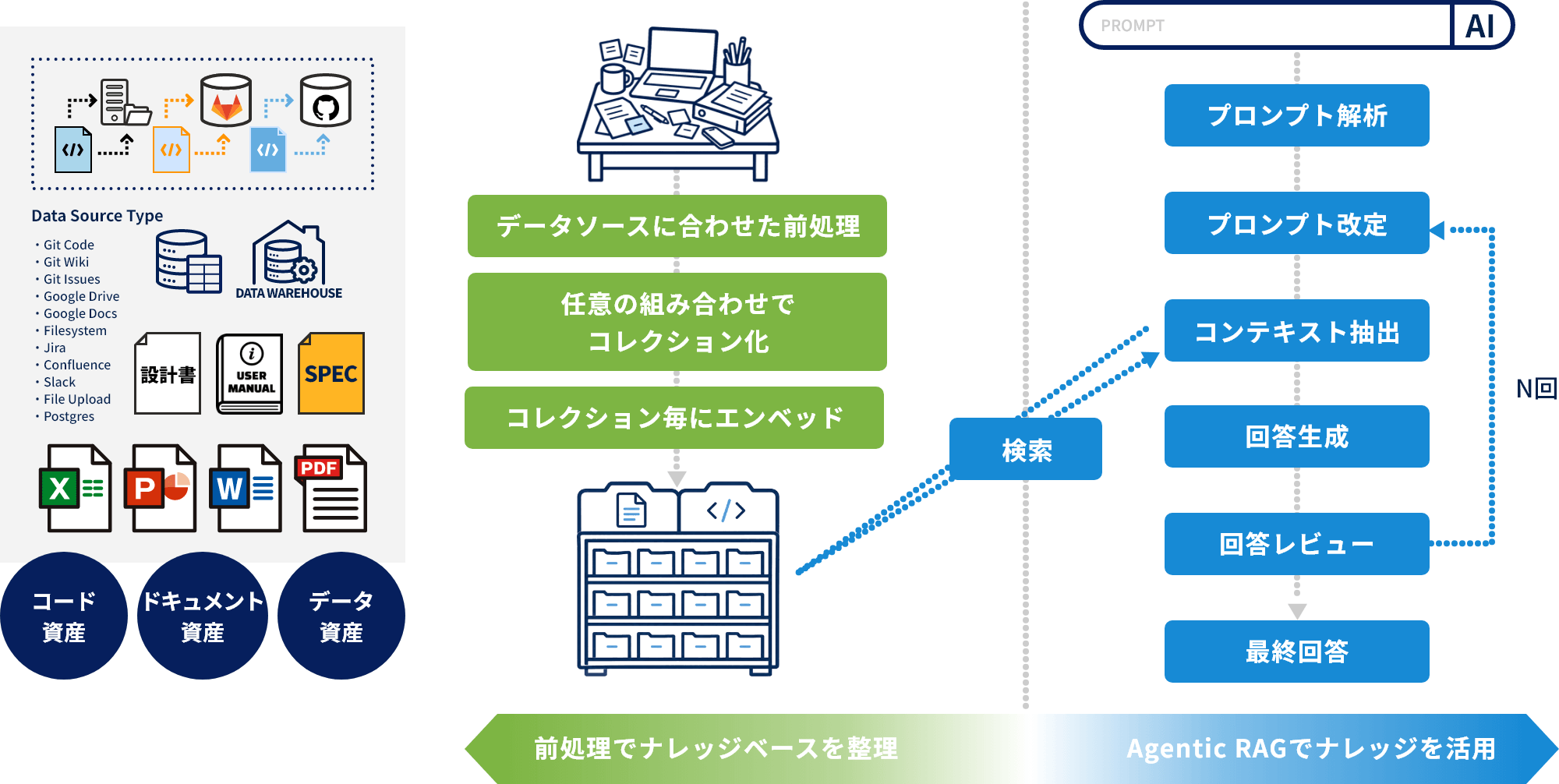
Krugle Biblioは単なるAgentic RAGではなく、前処理されたコレクション(コードおよび周辺情報)を検索することで回答精度を飛躍的に高めます。

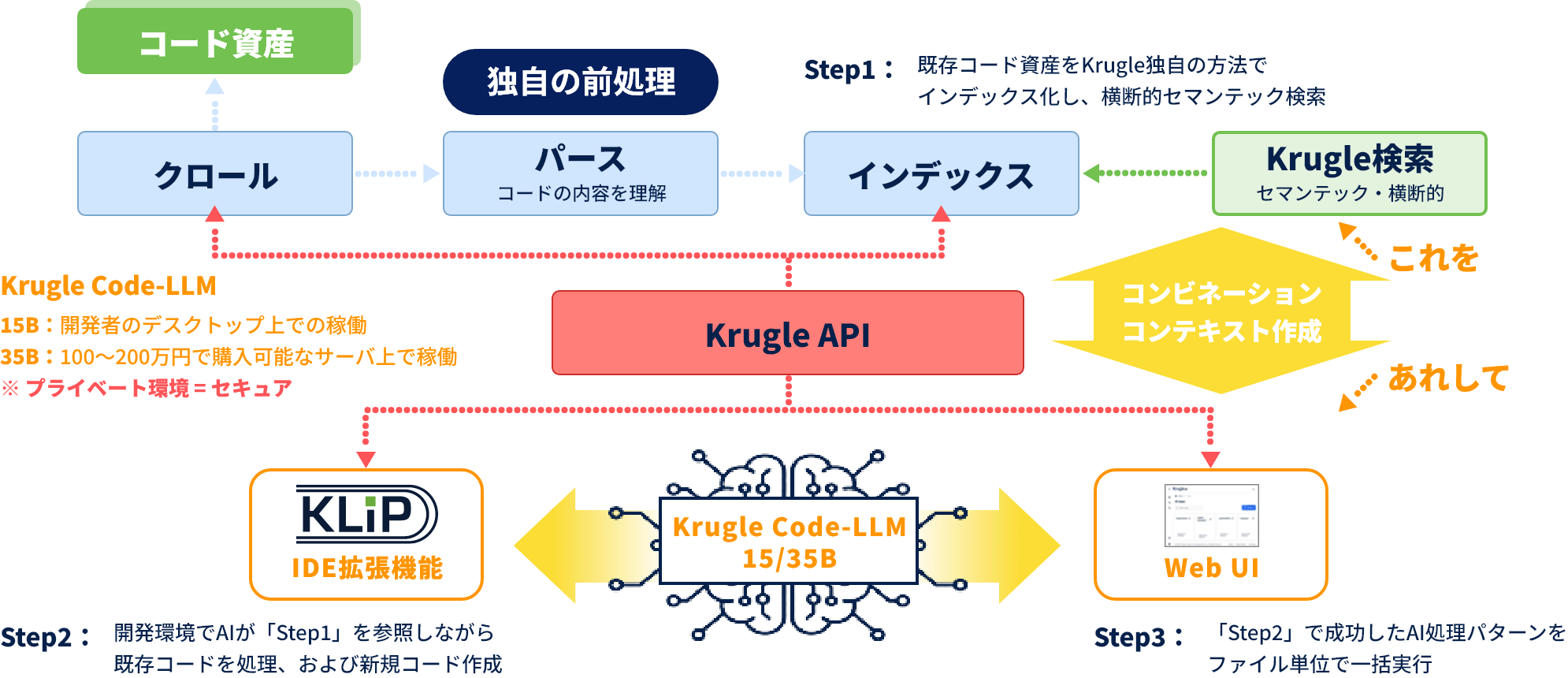
Krugle Searchは複数言語/複数ファイルに対し、横断的なセマンテック検索が可能です。
検索結果とKrugle Code-LLMを連携させて、システム従事者の様々な要望に応えます。